
No terms found for this post.
Most widely used fairness and explainability approaches, such as Equalized Odds, Equalized Opportunity, or Predictive Parity, analyse protected attributes like age, gender, or ethnicity in isolation. This can miss important interactions between attributes. A model may not discriminate based solely on age or gender, yet still systematically favor older men over other groups. Moreover, these metrics typically operate at the group level and offer little insight into individual decisions, even though contradictory outcomes for nearly identical individuals are far from rare. Addressing such cases requires a shift in perspective. Instead of asking only how a model behaves on average, we need to ask: What would have happened if things were just slightly different? This is the core idea behind counterfactual analysis.
In this blog, we explore counterfactual analysis in depth: what it is, how it works, and when this approach is most effective.
Counterfactual analysis meets the increased need for explanations on the individual model prediction level. But, by combining individual counterfactual explanations, they also give powerful insights into group level behaviour.
Each record in your dataset can have counterfactual explanations, which can also be referred to as counterfactual instances. They describe the minimally needed change necessary to change the instance’s prediction outcome. Most counterfactual analysis methods rely on generated counterfactual data, so they do not rely on the provided data to detect potential bias. This independence of relevant other occurrences in the available data makes counterfactual analysis a very powerful tool for detecting bias that otherwise would be overlooked.
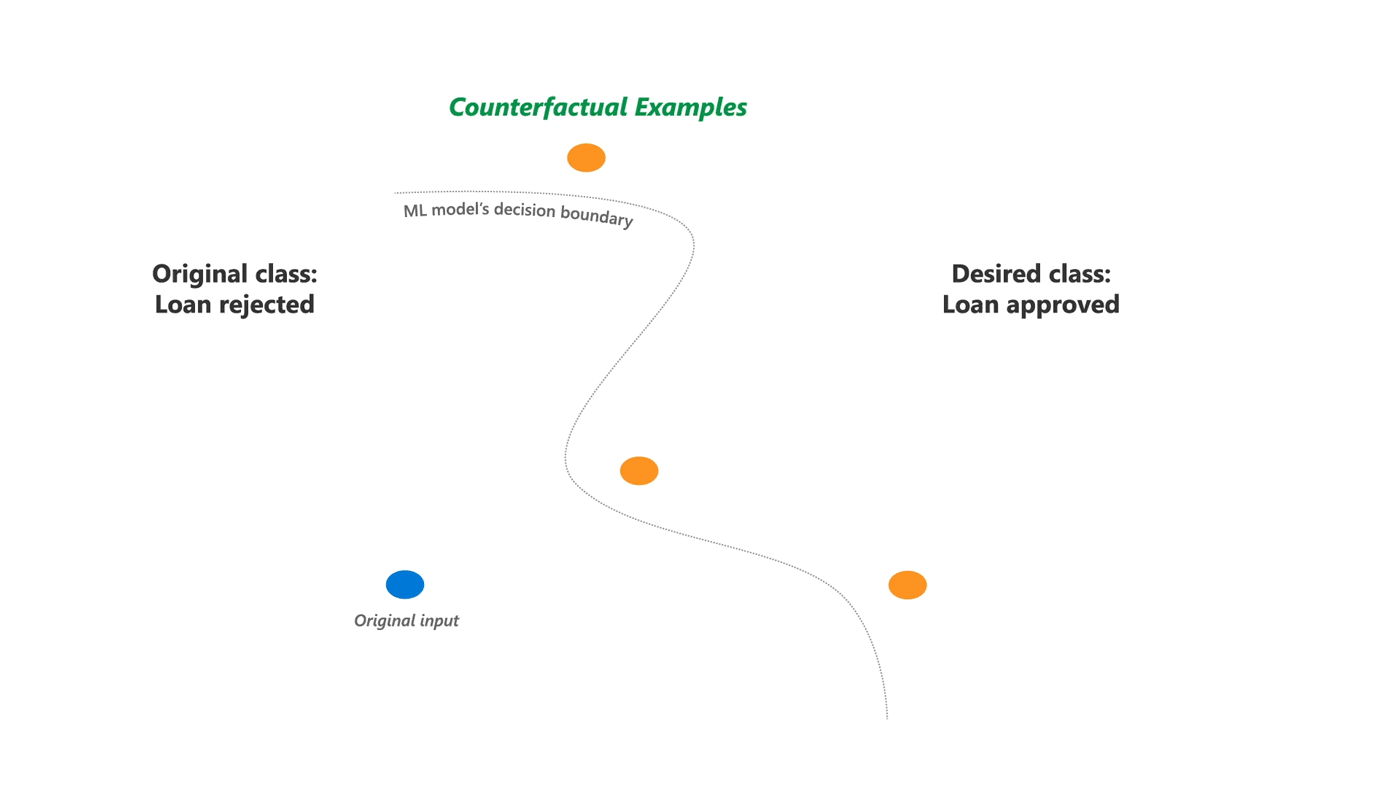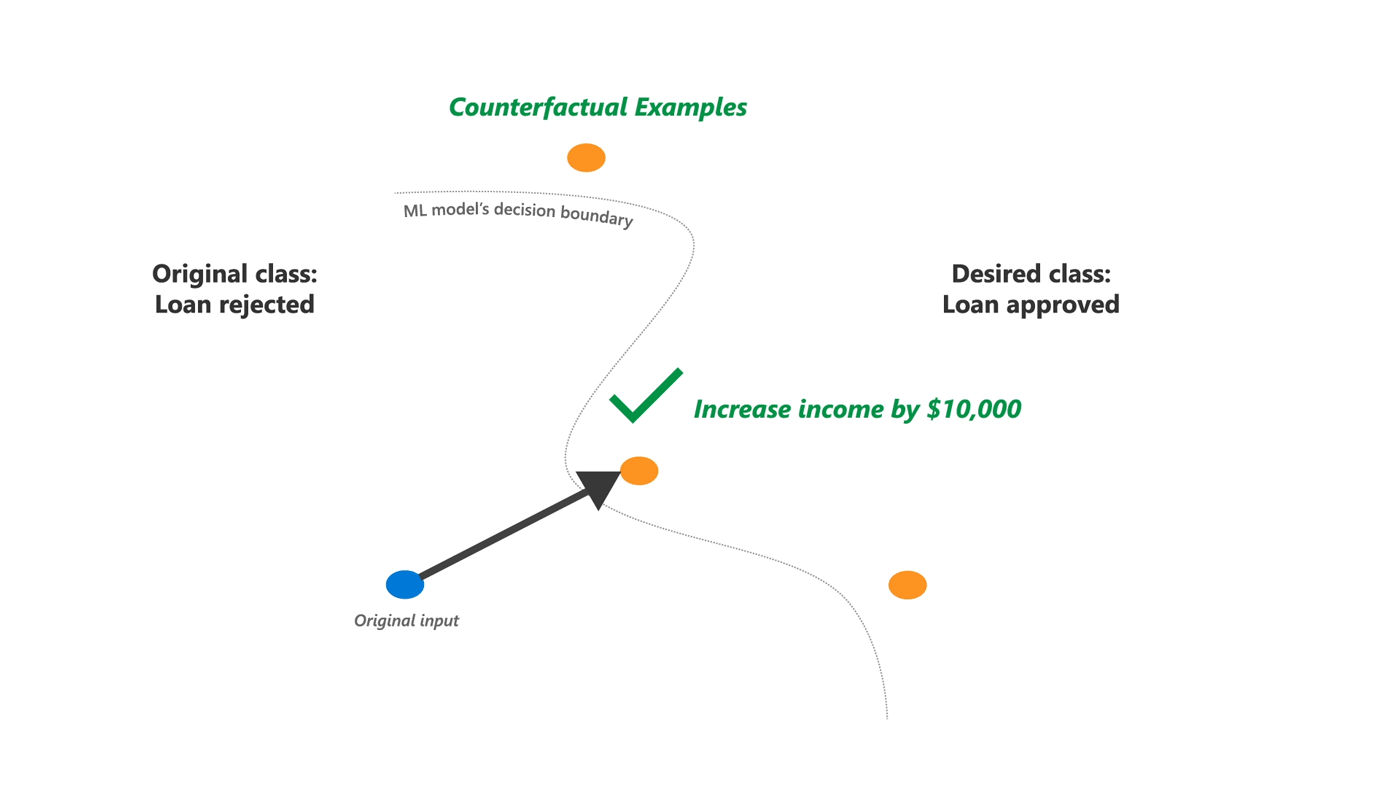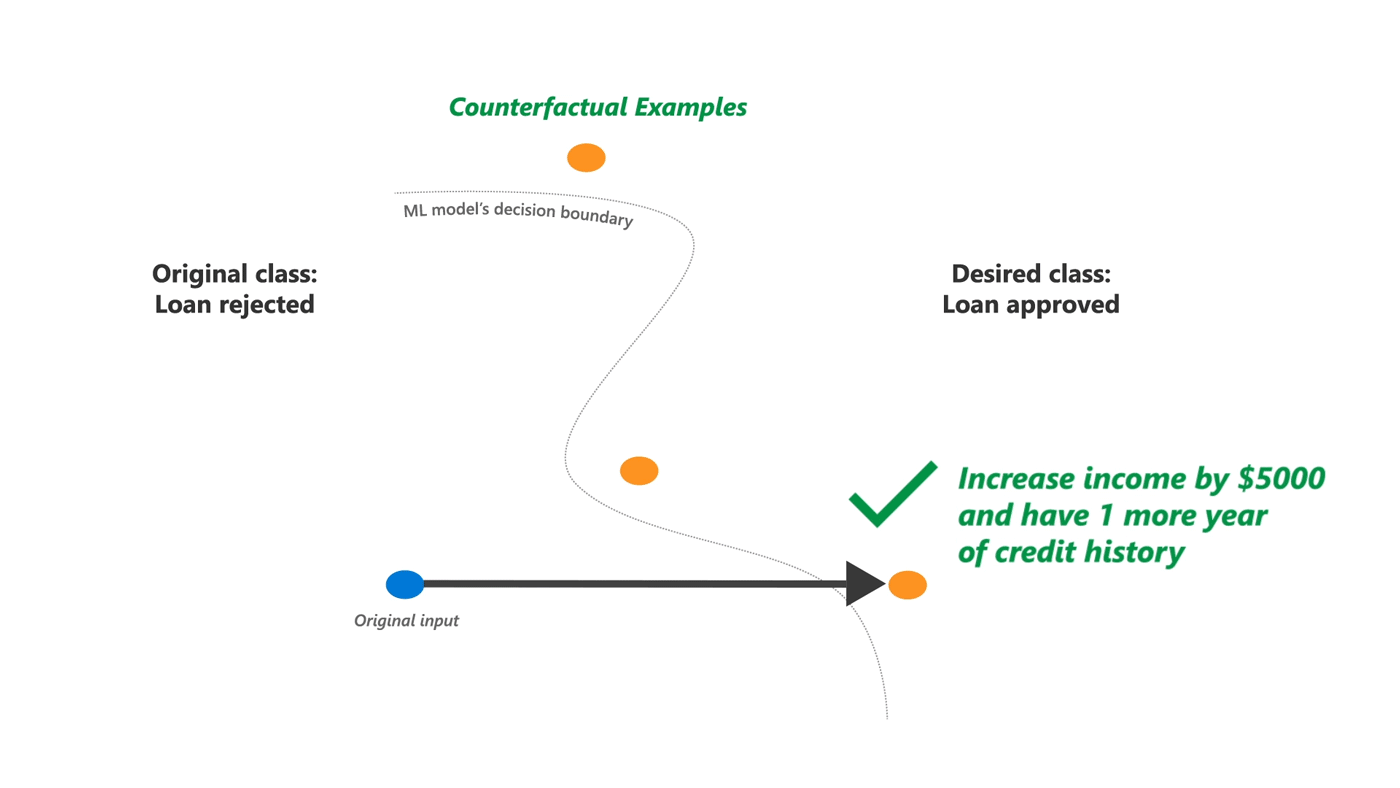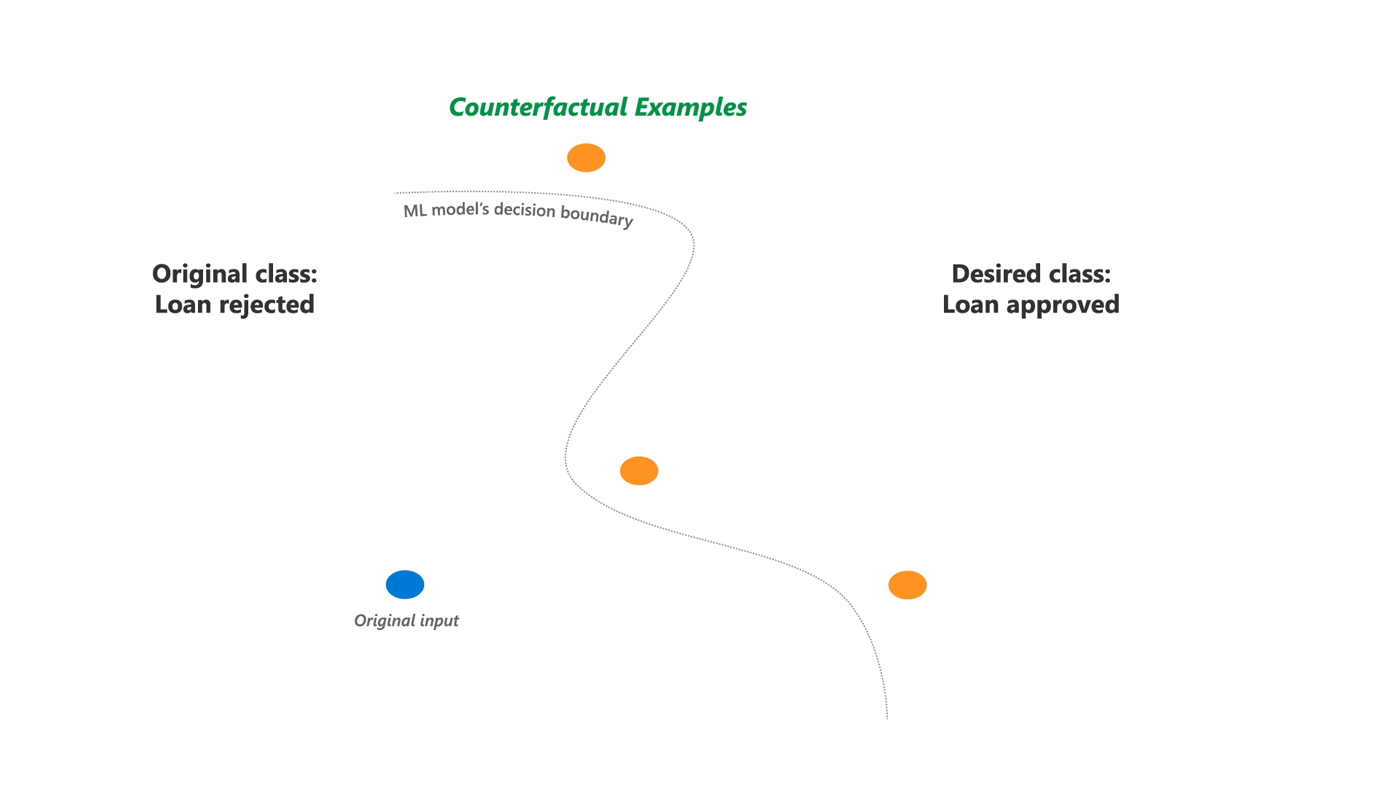
This minimally needed change can be measured by taking the Euclidean distance between a datapoint, and the most similar generated datapoint that has a different predicted outcome. This most similar datapoint is also referred to as a counterfactual example, or counterfactual instance.
During this blogpost we use a model for assigning loan applications as an example of an AI system. A counterfactual explanation of a rejected application is an application that is as similar as possible to the rejected application, however the model’s output has changed to approved. This insight into what minimal changes need to be made for a different outcome can be used to explain to the applicant why their application was denied. This transparency on individual model outcomes is exactly the level of openness the AI Act expects from high risk AI systems.
Counterfactual analysis also lends itself for fairness analysis on a group level. We can average the Euclidean distance between data points and their counterfactual examples. By comparing the averages of these two groups, we can judge if the model is biased towards one group or the other. We expect an unbiased model to have identical, or very similar, average distances between the original data points and their respective counterfactual explanations for similar groups.
This combination of individual and group level insights is highly relevant for AI governance and regulation. The AI act in particular obliges organisations to prove that models are not only robust and accurate, but also transparent and non‑discriminatory in high‑risk applications.
Link: https://pypi.org/project/dice-ml/
To illustrate the usage of counterfactuals developed a model to help us decide if we should accept a loan application or not. The model looks like this:
def predictLoanApplication(age, income, creditCards): if age < 36 and income > 50000: return 1 elif age >= 36 and income >= 38500 and creditCards <= 2: return 1 else: return 0