

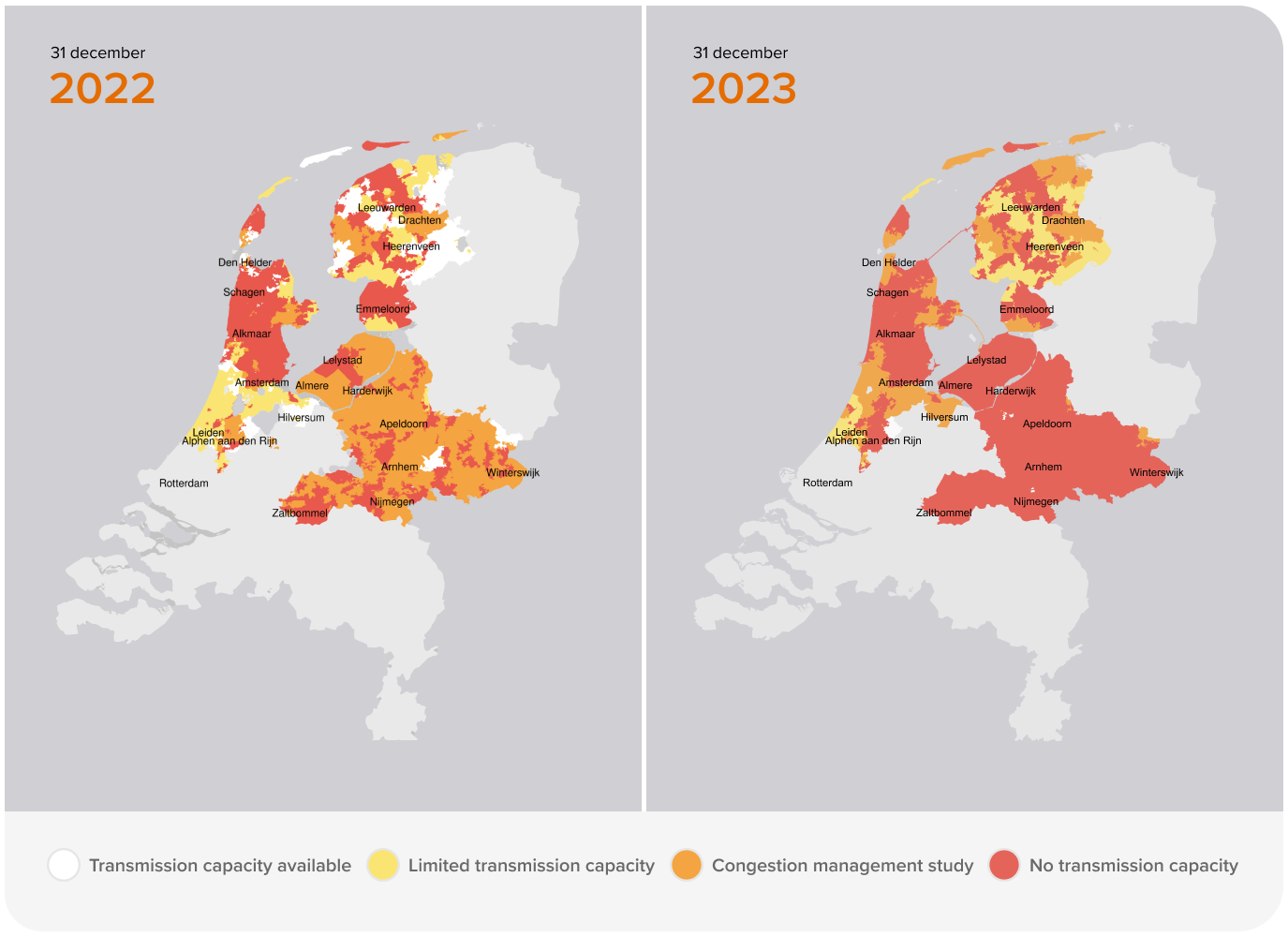
As such, Alliander has to renew and strengthen the entire network over the next decade, which is both costly and time-consuming. The challenge is determining where to begin with feasibility limitations (i.e. available workforce and resource availability). Which of the 36,000 networks should be improved first? This is where the DELVI project comes into play.
The Decision Enabler on Low Voltage Impact (DELVI) project focuses on predicting the health and future performance of these networks. It starts by forecasting how usage patterns could change in the future and predicts how this impacts the load profiles of customers. Furthermore, leveraging a stochastic approach, it uses these probabilities and Monte Carlo sampling to provide a what-if view into how the load might vary in the future on a 15-min timescale. It then performs a power-flow analysis to compute the behavior of these loads on the grid, indicating where possible contingencies or bottlenecks might arise. Its results are often used for strategic or operational planning.
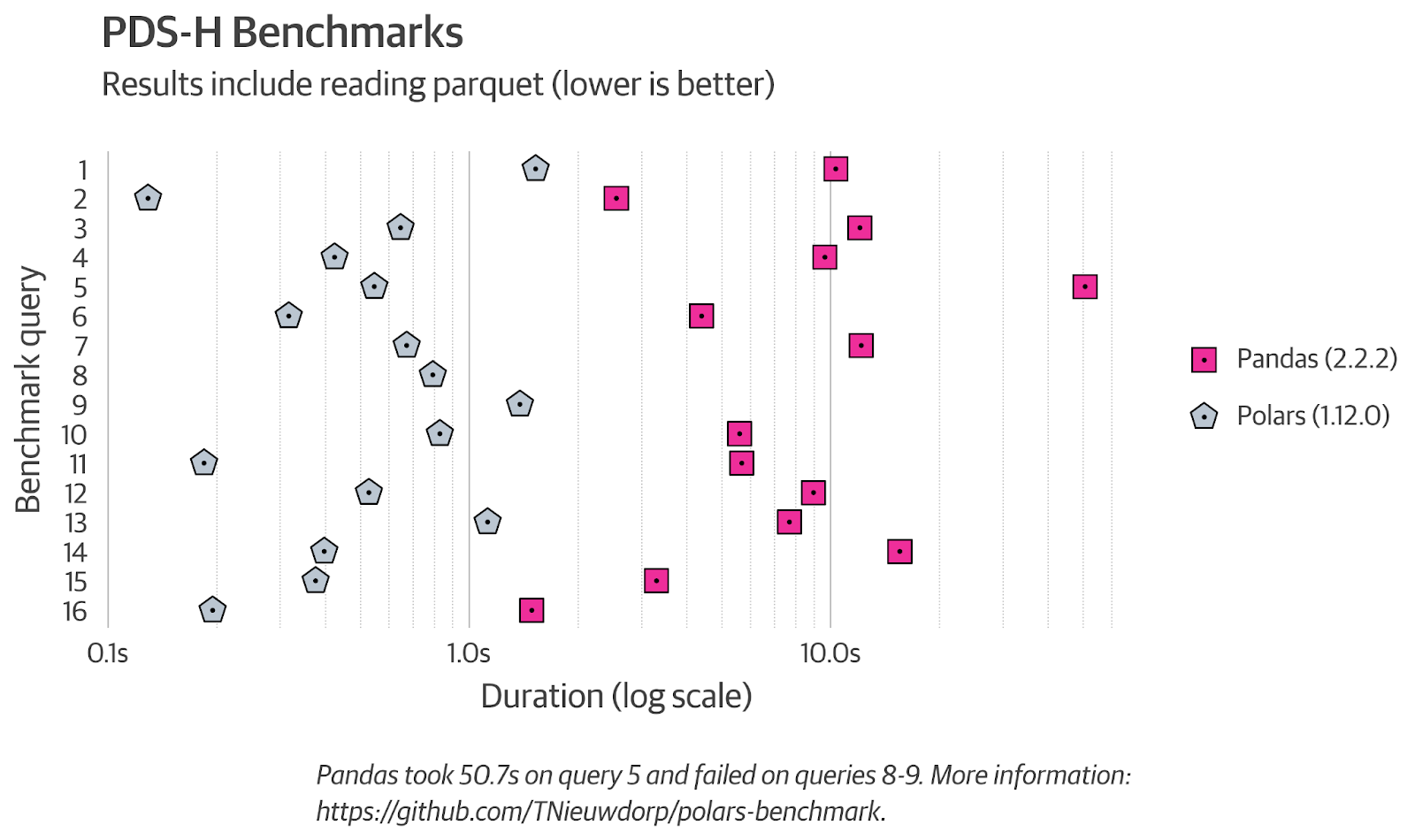
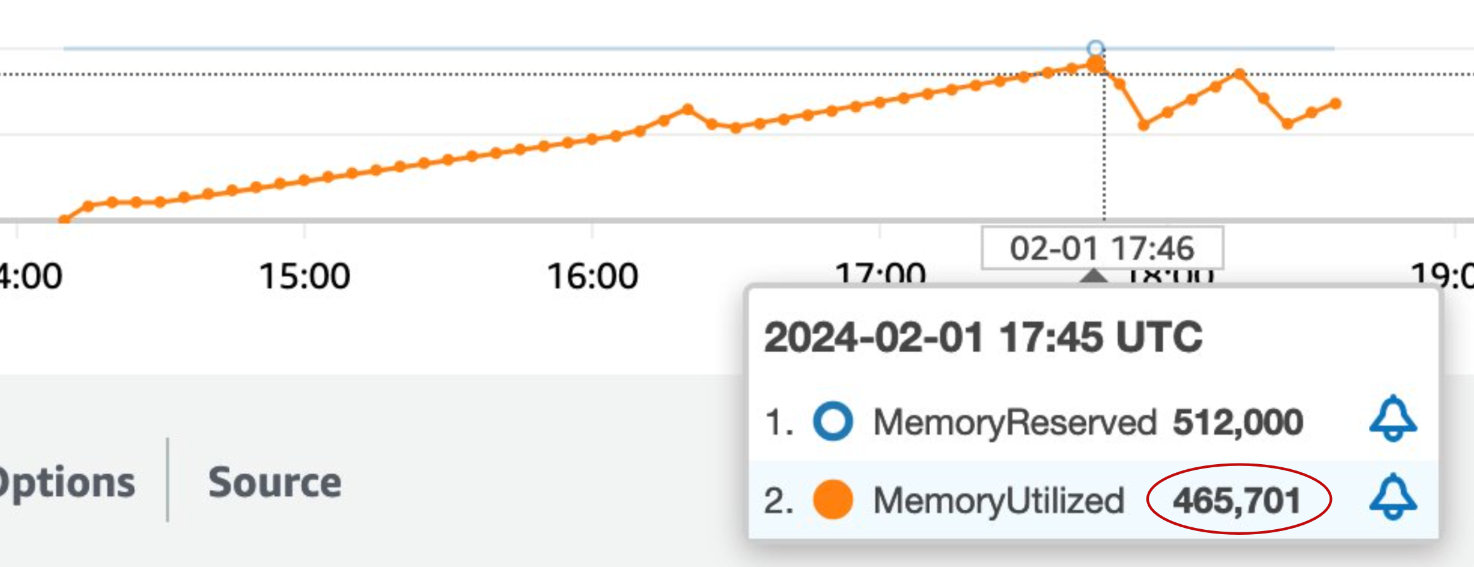
In the past, the codebase consisted of both Python and R. On the Python side, we used the pandas package for processing data. The R code was invoked using the rpy2 package. Processing one network could take up to five hours. The simulation could only sample 25 data points, as anything more would result in running out of memory. This process used over 500 GB of RAM, and the associated costs were enormous.
At a certain point, management set a target budget of €5,000 for processing all 36,000 networks. As this was obviously not feasible with the old codebase, something had to change.

Soon after we started writing, it hit us: why don't we use Polars for the DELVI project? We were certain it could handle the task, but the rest of the team wasn’t so easily convinced. At the time, Polars was still relatively unknown, and there wasn’t a stable release (no 1.0 version). Furthermore, the client also was concerned about the required effort to refactor a large pandas codebase. So, we had three key challenges to overcome:
Here's how we've overcome these challenges and what we've learned along the way.
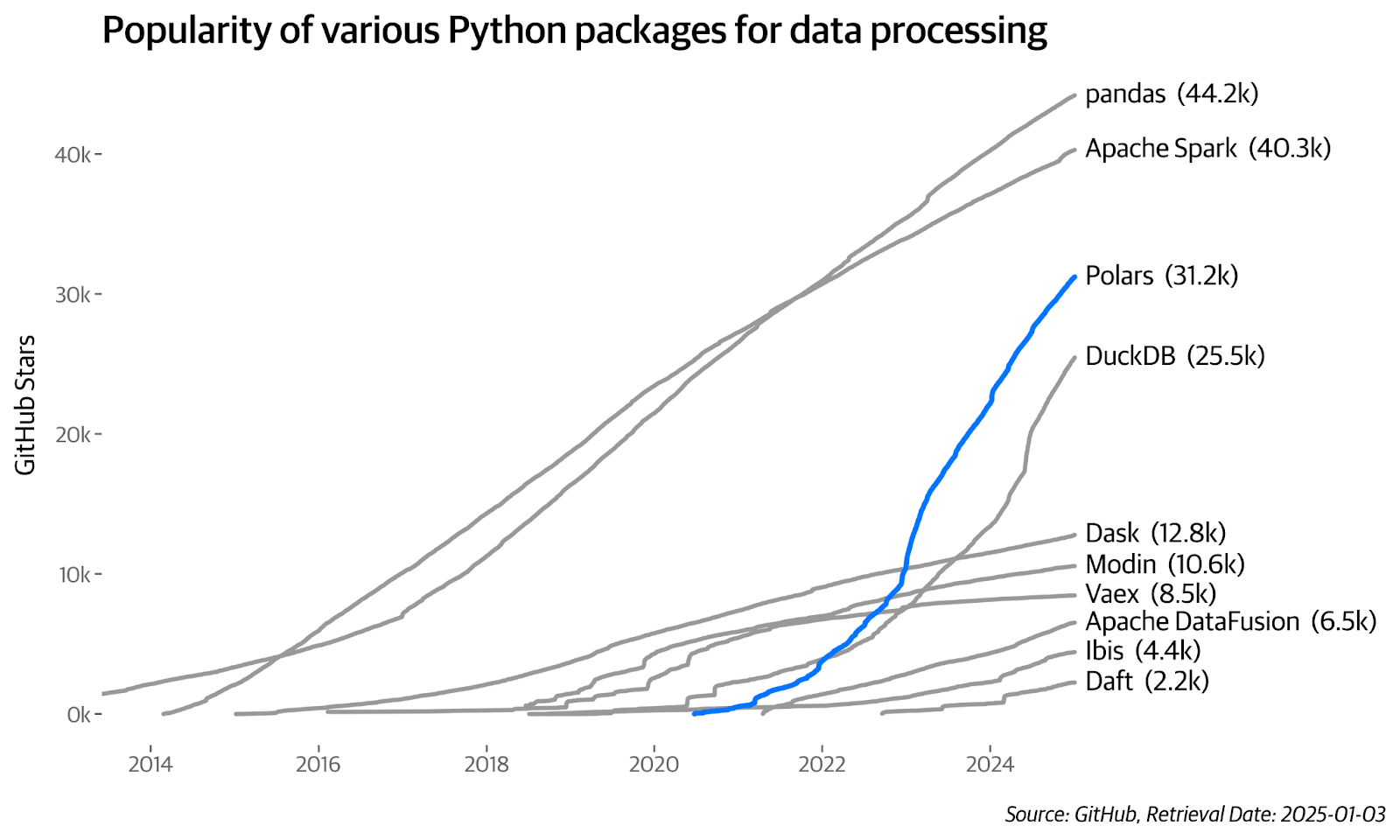
We’ve collaborated on this project for over 2 years, and along the way we’ve learned a couple of lessons we think are worthwhile sharing.
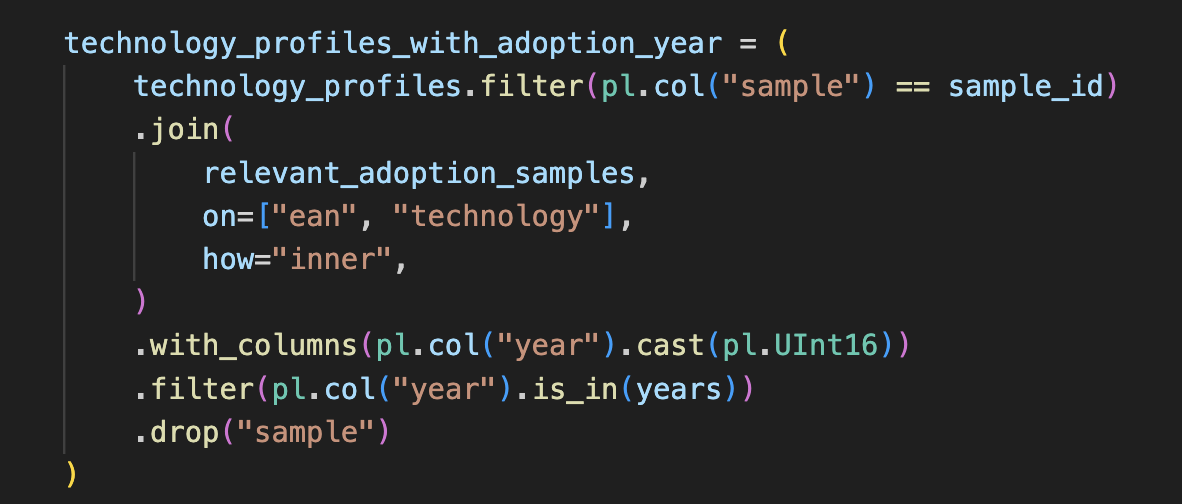
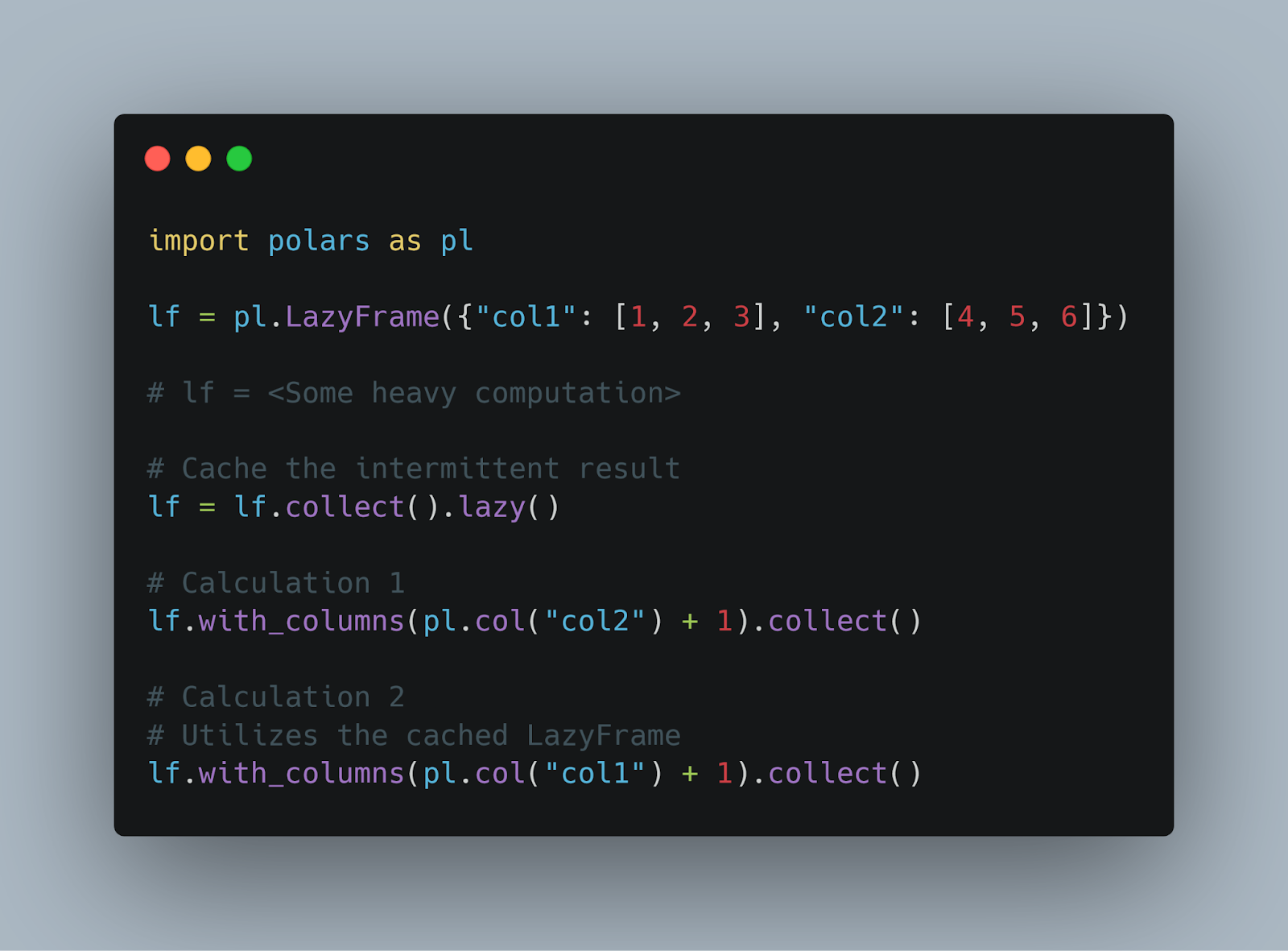
Switching from pandas to Polars was relatively easy because we didn't translate all at once. Because Polars allows for seamless conversion between Polars DataFrames and pandas DataFrames, you can take baby steps. If your pandas DataFrame is using the Arrow backend, the transition is even more efficient, as it’s a zero-copy operation.
After applying all the lessons learned, we were able to significantly improve our codebase. The processing time for a single network was reduced by 20%. The simulation could be based on 50 samples instead of 25, effectively doubling the amount of data processed. Memory usage was reduced by 92%, down from 500 GB of RAM to just 40 GB.
The entire codebase was converted to Python, eliminating the need for R, and fully migrated to Polars. This allowed us to process the entire grid (about 36,000 networks) for just 70% of the time and at a fraction of the cost. Had we used the old code, the project would have cost €140,000 to run, but with the new code, we brought that down dramatically to the budgeted €5,000.
* This fleet is used in mining and construction operations worldwide, which the aftermarket teams are aiming to keep running smoothly with minimal down-times. The Parts and Services division is responsible to proactively address potential issues in the mining and construction fleet.
The key takeaways from our experience with Polars are:
By applying these principles, we were able to significantly improve both the performance and maintainability of our codebase. We highly recommend giving Polars a try, and we hope our experiences will help others get started with it. If you would like to explore what opportunities might be available for your organisation, we’re very happy to help you. Get in touch!
Jeroen Janssens - Senior ML Engineer at Xomnia, Author of Python Polars
Thijs Nieuwdorp - Senior Data Scientist at Xomnia, Author of Python Polars
Bram Timmers - Data Science Engineer at Alliander

a.s.r., one of the Netherlands’ largest insurance and financial services providers, manages a wide portfolio, including insurance, pensions, mortgages, and capital management. As digital transformation accelerated their operations, Asset management...

The BI team faced some fundamental changes. After a restructuring of the data department the responsibilities of the developers changed, and the team inherited a complex reporting and data model landscape with varying levels of documentation.”

Enexis, one of the largest grid operators in the Netherlands, handles extensive networks of gas and electricity cables that run underground across the country. The company faces a continuous challenge: preventing hazardous incidents caused by excava...




